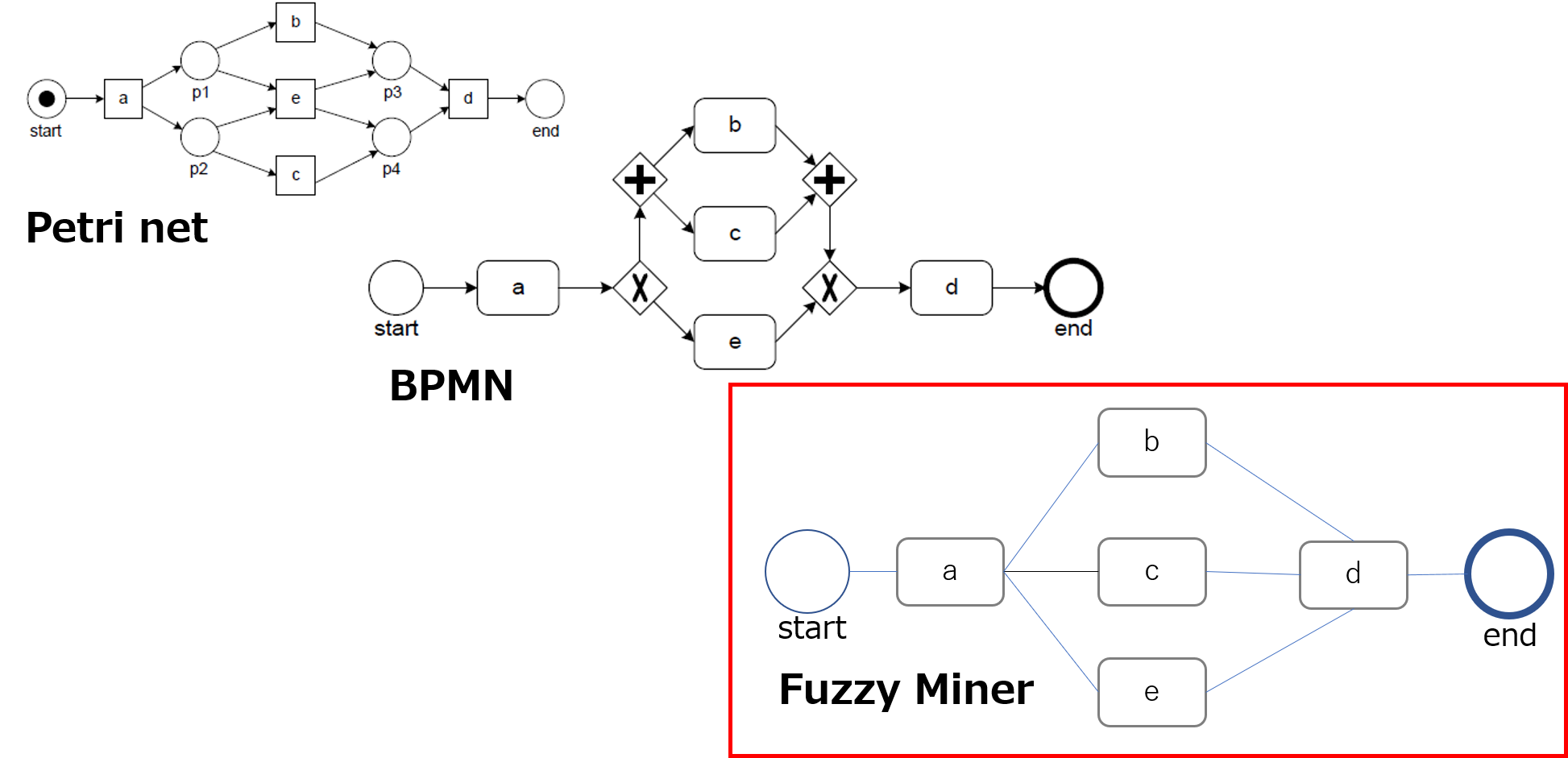
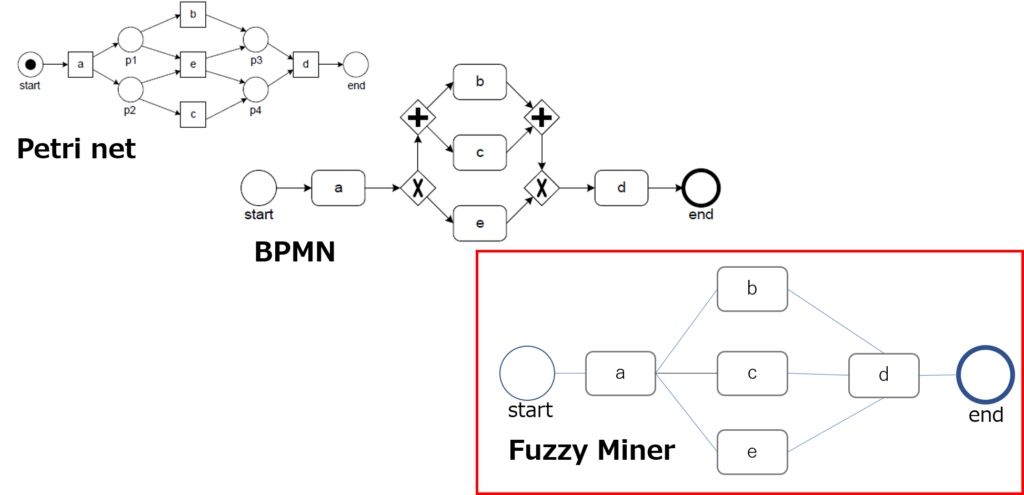
プロセスマイニングの基本機能である「プロセス発見」は、当初、ペトリネットがベースになっていたが、より現実に近いフローチャートを再現するために、様々なアルゴリズムが開発されてきている。ただ、業界有識者の話によれば、現在実用化されているプロセスマイニングツールのほとんどは、ファジーマイナーと呼ばれるアルゴリズムに基づいたもの(各社独自の改善は行っていると思われる)であると言われている。 同アルゴリズムは、一般にDFGs(Directly-follows Graphs)と呼ばれる。ペトリネットや、また業務手順をフローチャートとして記述するための世界標準であるBPMN(Business Process Modeling and Notation)と異なり、ノードとノードが直接(Directly)結びつけられたフローチャートがDFGsである。すなわち、分岐ノードが描かれないため、このアルゴリズムでは、どこでどのような分岐が発生しているのか、具体的には、排他的(OR)なのか、並行的(AND)なのか、といったことが把握できない。このため、現状のプロセスを自動的に再現するとはいっても、分岐が明確でない不完全なものになるというのが現実である。もちろん、これについては、BPMN形式のフローチャートへの自動変換や、前述したビジネスルールマイニングの採用などの機能改善が行われてきている。
図1 Petri net、BPMN、Fuzzy Minerのフロー図例 上図でわかるように、DFGsであるFuzzy Minerには、Petri netやBPMNのような分岐ノードが存在しないため、同じプロセスの表現でありながら、Fuzzy Minerでは分岐のルールを判別することができない。
このConvergence/Divergence問題は、プロセスマイニングの分析品質を左右する最大の課題と言える。そこで、近年では、プロセスマイニングのゴッドファーザー、Wil van der Aalst教授が率いる研究者たちが「Object-Centric Process Mining」(1)と称する独自の方法論により当課題の解決に取り組んでいる。 また、myInvenioには、マルチレベルマイニングという機能が実装されており、一つのプロセスについて複数の案件IDを設定することで、プロセスの集約・拡散の状況を加味したフローの再現を実現している。
Latest Process Mining Functionality, Challenges, and Future Evolutionary Trends
1 Latest Functions of Process Mining
Process mining tends to attract attention in terms of technology and tools, but its essence is a theoretical system and methodology (discipline) of data analysis. In fact, as the term “process” mining suggests, it can be considered as a type of data mining. However, unlike data mining, which is a broad concept that targets all kinds of events for analysis, process mining literally targets “processes” for analysis. The basic use of process mining is “process visualization,” and the visualization of processes facilitates the discovery of problems associated with the target processes. As a result, it can play a significant role in process improvement efforts.
1.1 Current Major Functions
As mentioned above, the research of process mining has started from the establishment of the methodology of “process visualization” and the development of tools. It is a function to automatically create a flowchart showing business procedures based on data extracted from IT systems used for business execution, and is called “Process Discovery. Since then, various functions have been implemented as research has progressed and tools have become more sophisticated. The following are the main analysis functions implemented in most of the current process mining tools.
Process Discovery
automatically create a flowchart of business procedures and calculate the frequency of work and time required.
Conformance Checking
compares and analyzes the current process (as-is) discovered based on data with the standard process (to-be), and extracts deviations from the current process.
Dashboards
A function to display the results of aggregation and analysis of target processes from various perspectives in various graphs and tables.
1.2 Latest Functions
In addition, in recent years, the most advanced process mining tools have begun to include the following latest functions.
Business Rule Mining
When there is a flow branching (decision node) in a target process, it automatically discovers the criteria (business rules) that determine the routing based on the data.
Simulation (What-If Analysis)
Simulate how much improvement can be expected by eliminating or automating some of the tasks in the current process visualized by the process discovery function.
Operational Support
For projects that are currently in progress, the system absorbs data related to business execution in real time, detects deviations in business operations, predicts future problems, and alerts the person in charge, suggests the best course of action, or automatically implements improvement measures.
Of the three latest functions mentioned above, business rule mining and simulation analyze past data, i.e., data that has already been completed, while operational support focuses on supporting smooth business execution by sequentially processing data related to unfinished projects. In this sense, it can be said that operational support is a form of IT solution that goes beyond the framework of analysis methodology. For this reason, Ceronis, the largest company in the process mining industry, calls this function “EMS (Execution Management System).
2 Issues to be overcome to make process mining better to be used
As seen in the acquisition of Signavio, a major tool vendor, by SAP and myInvenio by IBM, process mining is increasingly recognized as an important tool that is part of IT solutions. However, there are issues that need to be overcome in order for it to be used properly in business practices and to bring results. In this section, I would like to present the main issues from two perspectives.
2.1 Difficulties in data preprocessing
In data mining, it is said that about 80% of the total time required is spent on data preprocessing such as data collection, extraction, and cleaning. The same is true for process mining. It takes a lot of effort to properly integrate dozens to hundreds of data files extracted from various IT systems, to correct dirty data such as omissions and garbled characters, and to create a “data set” that can be fed into tools for analysis. Factors that make data pre-processing in process mining difficult include the fact that the source of data extraction is various business systems, and thus an understanding of the business systems is necessary. In addition, in order to create a data set to derive analysis results that contribute to business process improvement, it is necessary to understand the business itself and to have some familiarity with business improvement methods.
2.2 Analysis quality of tools
There are two issues that need to be addressed regarding the quality of analysis. One is the limitation of DFGs (Directly Follows Graphs), and the other is the Convergence/Divergence problem.
2.2.1 Limitations of DFGs
The basic function of process mining, “process discovery,” was initially based on Petri nets, but various algorithms have been developed to reproduce flowcharts closer to reality. However, according to industry experts, most of the process mining tools currently in practical use are said to be based on an algorithm called fuzzy miner (each company is believed to have made its own improvements).
This algorithm is commonly called DFGs (Directly-follows Graphs). Unlike Petri nets and BPMN (Business Process Modeling and Notation), which is the world standard for describing business procedures as flowcharts, DFGs are flowcharts in which nodes are directly connected to each other (directly). In other words, since branching nodes are not drawn, the algorithm cannot grasp where and how the branching is occurring, specifically, whether it is exclusive (OR) or concurrent (AND). For this reason, even if the current process is automatically reproduced, the reality is that the branching is not clear and incomplete. Of course, functional improvements have been made in this regard, such as automatic conversion to BPMN format flowcharts and the adoption of business rule mining as mentioned above.
2.2.2 Convergence/Divergence Problem
In process mining, three items, “case ID,” “activity (event),” and timestamp, are essential to draw a flowchart by bundling each activity performed for a case processed in the target process. For example, in the case of an invoice processing process, the individual invoice number attached to each invoice and the activities such as “receipt,” “confirmation,” “approval,” and “payment” for that invoice are extracted from the IT system along with the time stamp.
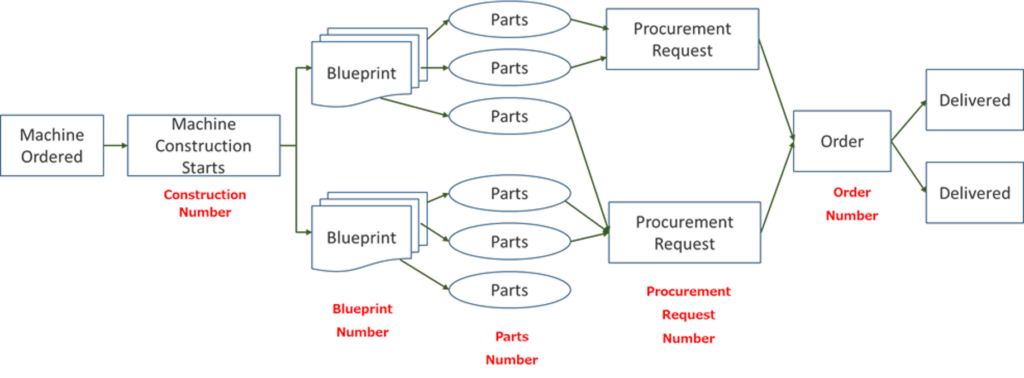
What we often face in the actual process is that there is no single case ID. Let’s take a concrete example. The figure below shows a general image of the process of an engineering company from order receipt to material procurement.
Since the ordered machine must be manufactured based on the specifications of the ordering company, after receiving the order, the company first designs the machine, then identifies the necessary materials and parts based on the blueprint, and then places an order with the supplier. Since multiple blueprints are created for a single machine, the Blueprint Number is used in the design stage. In addition, the Parts Number is used to identify materials and parts, and at the time of procurement, multiple parts are combined into several parts and a procurement request is issued. In this case, a Procurement Request Number is assigned. In addition, the multiple procurement requests are aggregated to each supplier and an order is placed. In this case, the Order Number becomes the ID for management.
In this way, the processes of convergence and divergence are commonly seen in practice as a single case is processed. In the conventional approach, the construction number at the beginning of the process is used as the case ID, and the entire process is analyzed up to the procurement of materials, but if there is convergence or divergence in the process, a process that is far from the actual situation is reproduced. (For example, the diffused part is recognized as a mere repetitive task.)
This Convergence/Divergence problem is the biggest issue that affects the analysis quality of process mining. In recent years, researchers led by Professor Wil van der Aalst, the Godfather of Process Mining, have been working on solving this problem using a unique methodology called “Object-Centric Process Mining” .
3 Future Direction of Evolution
We have already mentioned that process mining is playing a role as a business support solution beyond the framework of data analysis. In this section, we will discuss how process mining will evolve in the future from a bird’s eye view.
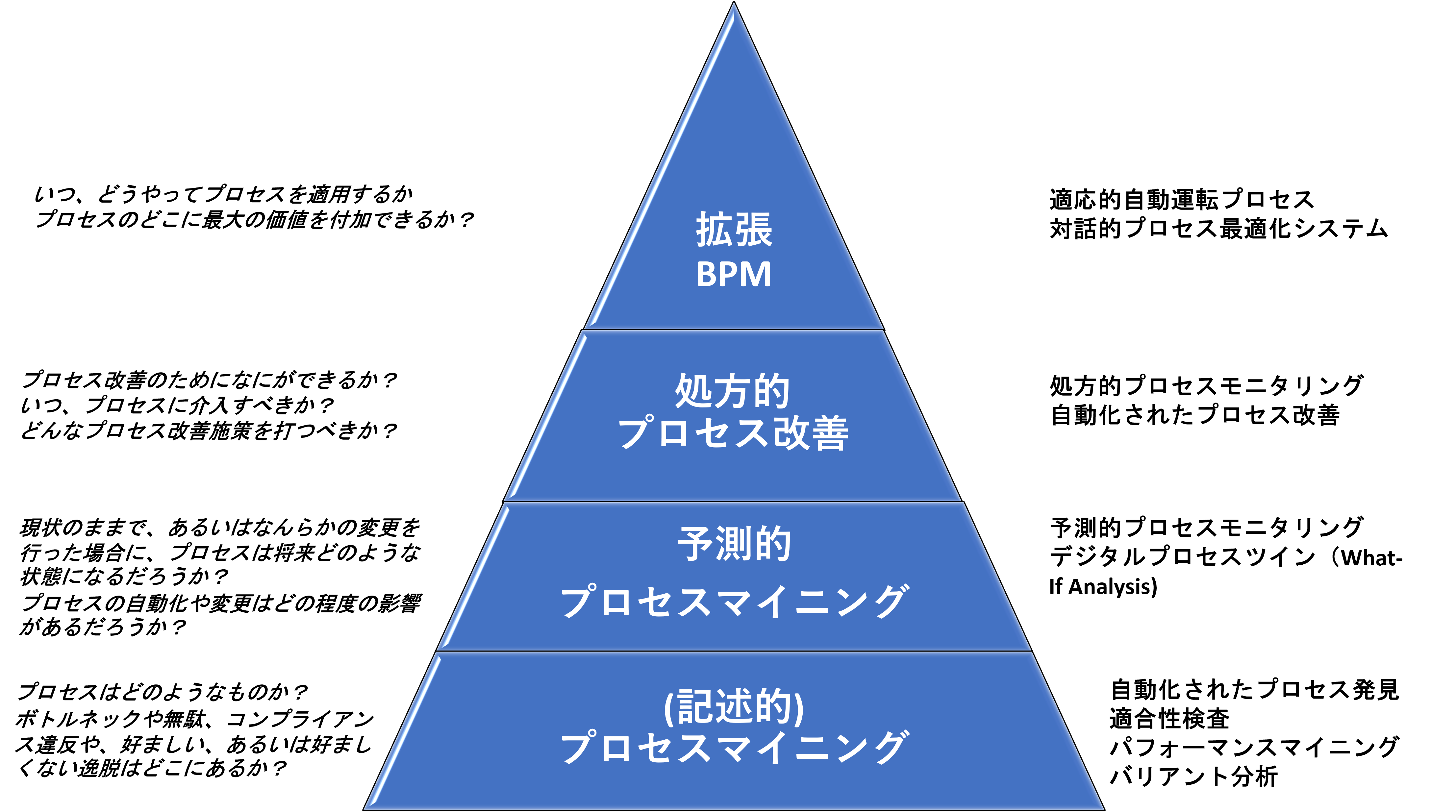
3.1 Process Mining 1.0
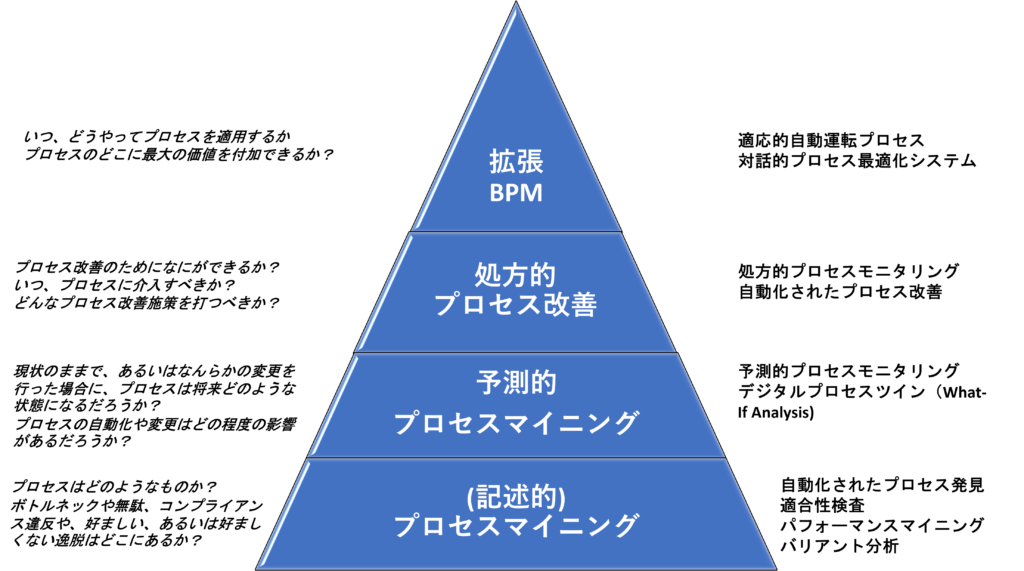
Process mining is. The basic function of process mining was “process discovery,” which automatically reproduces the current process from data. This is a “Descriptive Analysis” in that it depicts the current state as it is.
However, what we originally wanted to do was to extract problem areas such as inefficiencies and bottlenecks hidden in the process. In other words, we need to find out what is wrong with the process. Therefore, there is an additional function that can easily tell us where the problem is, such as the processing time of this part is too long or there are too many repetitions. This is a function that belongs to Diagnostic Analysis. In process mining tools, it is generally named “Root Cause Analysis.
The above is an analysis function for historical data, and should be called Process Mining 1.0.
3.2 Process Mining 2.0
When process mining starts to take in uncompleted, i.e., ongoing, case data in real time as a target of analysis, it becomes possible not only to detect deviations but also to predict how long it will take to complete the currently running case, and to predict deviations that may occur in the future. In addition, it is possible to predict how long it will take to complete a case that is currently running, and to predict future deviations. The number of tools that implement such predictive analysis is increasing.
Furthermore, based on the prediction results, tools that can suggest what actions should be taken now to shorten the time required or to prevent future deviations from occurring are also emerging. This is the function of “Prescriptive Analysis”.
Such process mining analysis that deals with incomplete data is a major upgrade of the existing process mining 1.0, and can be called process mining 2.0.
Although predictive and prescriptive analyses are still in their infancy and their reliability is not necessarily high, it is certain that they will be introduced to many companies as valuable solutions to support smooth business execution based on enterprise systems such as ERP through further technological progress in the future.
グローバルに展開する保険会社、AIGでは様々な業務プロセス改善に取り組んでいます。特に、米国AIGの”Data-Driven Process Optimization”と呼ばれる部署では、プロセスマイニング、シミュレーション、BIを組み合わせることで改善成果を積み重ねています。
Data-Driven Process Optimization部署では、プロセス改善の一連の手順を「プロセス風洞(Process Wind Tunnel)」と呼んでいます。自動車や航空機、建築物などの設計においては、風洞に模型を置いて風の流れ等を測定する「風洞実験」を行います。同様に、プロセスの改善にあたって、シミュレーションによる改善成果の予測を行った上で改善施策に展開するという手順を踏んでいるのです。
 Marlon Dumas – Professor at University of Tartu | Co-founder at Apromore
Marlon Dumas – Professor at University of Tartu | Co-founder at Apromore