
Introduction to Process Mining (8) Process Mining Algorithm Basics
今回は、プロセスマイニングによるプロセスモデル(フローチャート)再現の基本原理であるアルゴリズムについて、わかりやすさを優先し、簡易的に説明します。
詳細な技術的解説は、プロセスマイニングのバイブルである『プロセスマイニング Data Science in Action』(Wil van der Aalst著、インプレス)をお読みください。
プロセス発見 – Process Discovery
プロセスマイニングは当初、「Automated Business Process Discovery」(自動的に業務プロセスを発見する)と説明されていました。ITシステムから抽出したイベントログデータから、対象プロセスの流れ(業務手順)を自動的に再現することが最も基本的な機能だからです。
現在は、単にプロセスを発見するだけでなく、参照プロセス(to beプロセス)との比較分析を行う「適合性検査」や、未完了の案件について予測を行ったり、逸脱発生時にアラートを流すなど、高度な機能が次々と実装されています。
したがって、プロセスマイニング=プロセス発見とは言えなくなってきたものの、プロセス発見という機能がプロセスマイニングの核となる機能であり、また分析の出発点であることは依然変わりません。
さて、イベントログは下図あるようなフラットなデータです。イベントログからプロセスモデル(フローチャート)を再現するためには、案件ID、アクティビティ、タイムスタンプの3項目があればいいのですが、初めてプロセスマイニングを知った方は、どうやってフローチャートを描くのか不思議に思われるようです。もちろん、裏には、一定の処理ロジック、すなわち「アルゴリズム」が存在します。
このアルゴリズムはプロセスマイニング固有であり、一般的なデータマイニングツールには備わっていません。したがって、プロセスマイニング分析を行い、プロセスを可視化したい場合には、プロセスマイニングツールを利用する必要があります。
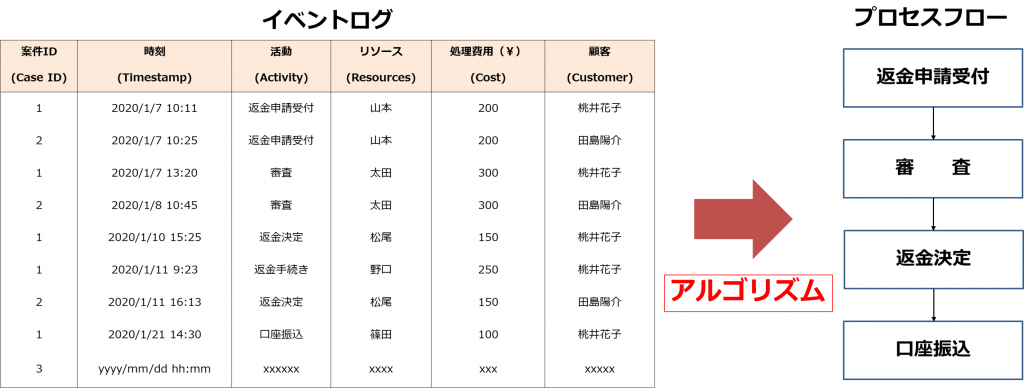
プロセスモデル(フローチャート)の再現
では、イベントログからフローチャートをどのように作成するかを簡易的なサンプルデータでご説明しましょう。
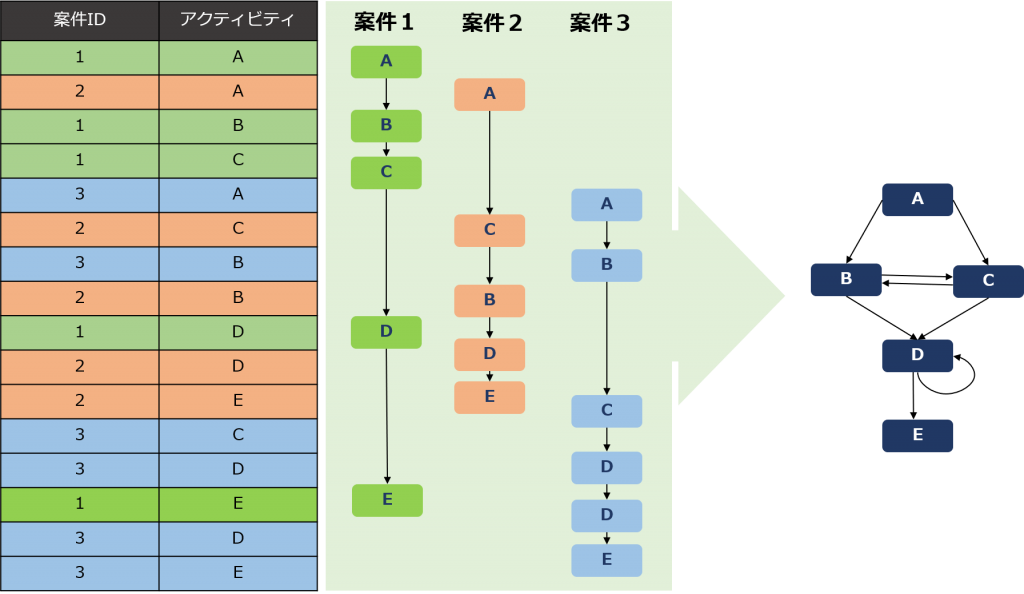
下図のデータは、案件ID(1~3)とアクティビティ(A~E)のみ。タイムスタンプは略してありますが、上から下に時間が経過している、つまり上の行にあるアクティビティほど古い時間に行われているということになります。
まず案件1についてアクティビティを拾ってみましょう。色分けしてあるので簡単です。緑色のアクティビティ、すなわちA→B→C→D→Eです。同様に、案件2(オレンジ)、案件3(青)についてそれぞれのアクティビティのフロー図が下図の中央にあります。
言うまでもないことですが、Aを起点として終点のEに至る道筋=トレースは、案件毎に異なっています。アクティビティの順番が入違ったり、同じアクティビティが繰り返されていたりしていますね。どんなプロセスであれ、その辿る道筋=トレースは複数のバリエーションがあるのが一般的です。
プロセスマイニングでは、案件ごとの個別の道筋を分析することもありますが、まずはこうした複数のバリエーション全体をうまく説明できる「プロセスモデル」を作成します。(下図右端の濃紺のフローチャート)たとえとしては正確ではありませんが、バリエーションの「最大公約数」を見つけるようなものです。
こうして、イベントログに含まれる複数の業務手順のバリエーションから、全体に当てはまりのよいプロセスモデルを作成するのがプロセスマイニングのアルゴリズムです。なお、プロセスマイニングツールに触れたことのある方はお分かりかと思いますが、このプロセスモデルの抽象度は自由に変更することが可能です。すなわち、全体の流れをざっくり把握できる抽象度の高いモデルから、すべてのバリエーションを再現した、最も抽象度の低い詳細なモデルまで、ツールの機能として「粒度」を変更できる可変スライダーが実装されています。
プロセスモデル作成の流れ(イメージ)
さらに、もう少し詳しくアルゴリズムの原理を説明しましょう。
前項同様、わかりやすいように、タイムスタンプを省いて以下のような4つの案件が含まれたイベントログからのフローチャート作成を考えてみましょう。ここで、アルファベットは各アクテイビティであり、(A,B,C)のログは、A→B→Cという時間的順番で行われたことを意味します。
わかりやすいように、タイムスタンプを省いて、以下のような4つの案件が含まれたイベントログからのフローチャート作成を考えてみましょう。
CASE_1 (A,B,C)
CASE_2 (A,B,D)
CASE_3 (A,E,C)
CASE_4 (A,B,C,B,C)
ここで、アルファベットは各アクテイビティであり、(A,B,C)のログは、A→B→Cという時間的順番で行われたことを意味します。
まず、CASE_1のログからフローチャートを描きます。

シンプルですね。
次に、CASE_1に加えてCASE_2も考慮します。
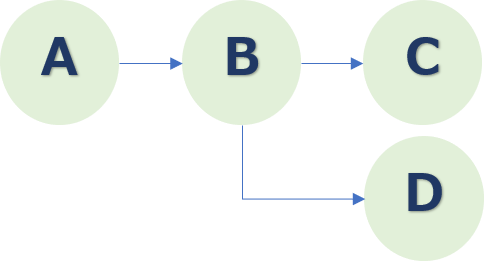
A→B→Cだけでなく、A→B→Dというパタンも存在したことがわかったので、BからCとDに分岐するフローチャートが描かれました。
さらに、CASE_1、CASE_2、CASE_3の3つの案件を考慮したフローチャートです。
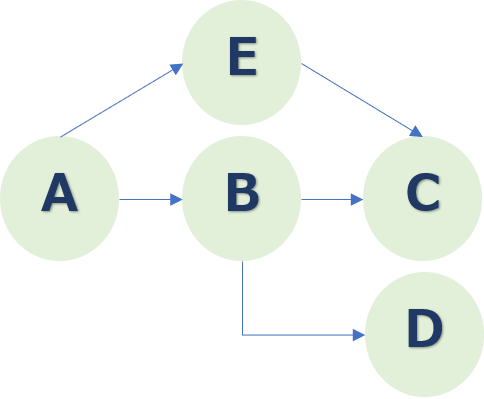
Aに続くのはBだけでなく、Eが続く手順もあるのでこのようなフローになります。
最後に、CASE_1からCASE_4までのすべてを考慮したプロセスモデルは以下の通りです。
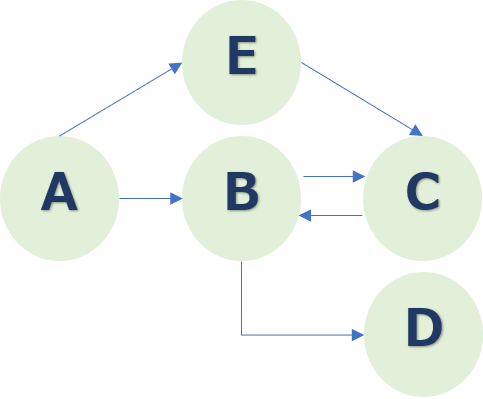
B→Cだけでなく、C→Bと戻る手順も存在していることがわかります。手戻り発生です。
以上の例では4案件だけでしたが、実際の業務プロセス分析では数万件、数十万件の案件のイベントログに基づいて、上記のようなフローチャートを再構成していくわけです。
アルゴリズムの種類
イベントログからプロセスモデル(フローチャート)を再現するアルゴリズムも日々進化しています。
プロセスマイニングは1999年、オランダでの学術研究からスタートしていますが、当初は「アルファアルゴリズム(アルファマイナー)」が用いられました。ただ、アルファアルゴリズムには、現実のプロセスを十分に再現できないというロジック上の制約があるため、研究が進むにつれ、以下のような様々なアルゴリズムが開発されています。(それぞれに、優れている点と劣っている点があり、どれが最も優れたアルゴリズムか、ということは一概に言えません)
・ヒューリスティックマイナー
・インダクティブマイナー
・スプリットマイナー
現在入手可能なプロセスマイニングツールは世界に30ほど存在しますが、それぞれなんらかのアルゴリズムをベースに、精度を高めるためのカスタマイズを施していると思われます。
ユーザーとして留意しておきたいことは、同じイベントログだったとしても、様々なツールによって再現されたプロセスモデル(フローチャート)を比べてみたら、若干の違いがあるだろうということです。(まったく違うということはないにしても)なぜなら、それぞれ異なるアルゴリズムを実装しているからです。