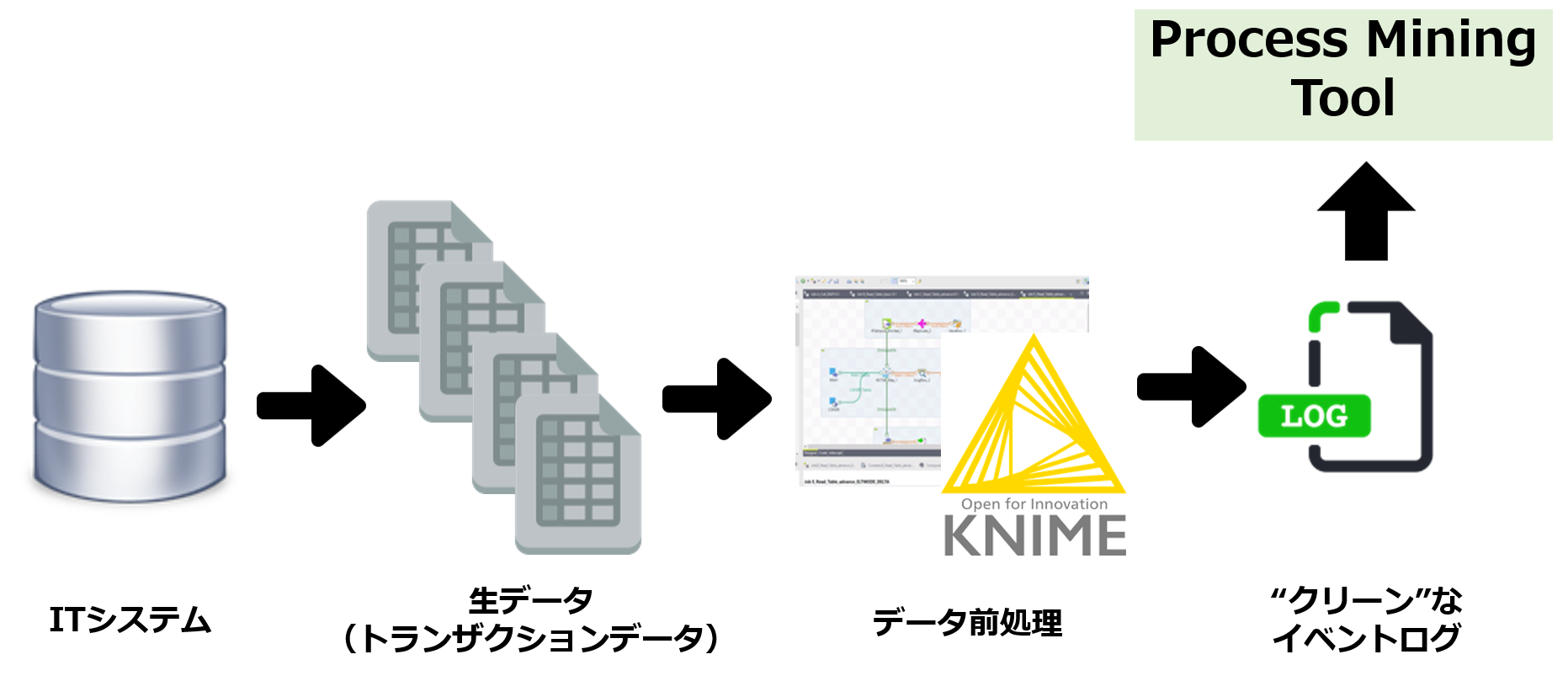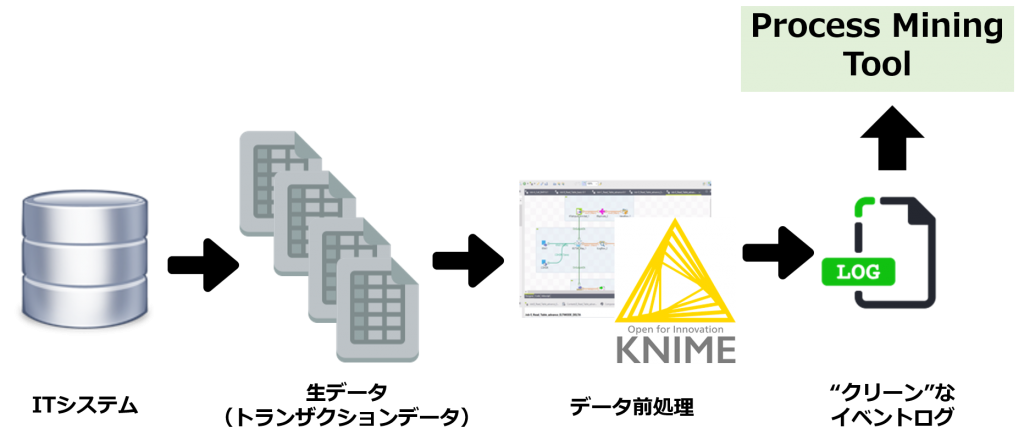
Introduction to Process Mining (3) Business environments which make process mining
indispensable English follows Japanese. Before proofread.
今回は、プロセスマイニングが重要、かつ不可欠となっていく、ビジネスを取り巻く環境変化について解説します。
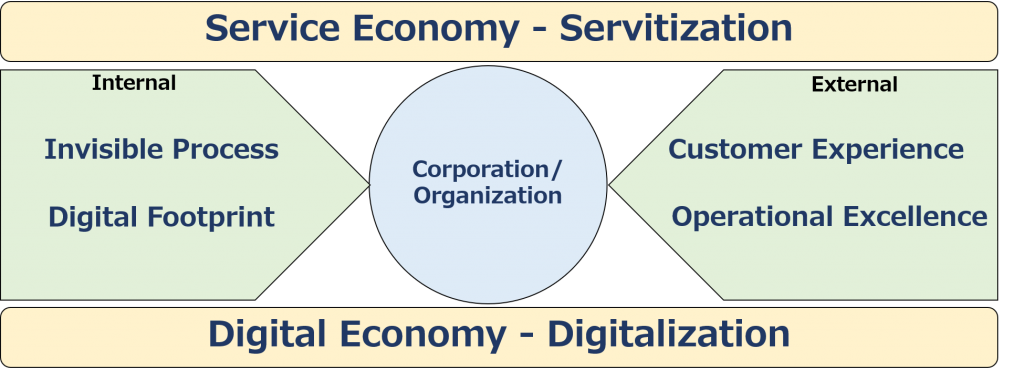
まず、社会全体の大きなトレンドとして挙げたい環境変化が2つあります。サービス化による「サービスエコノミー」、そして、デジタル化による「デジタルエコノミー」です。
サービスエコノミー – サービス化
これまでの経済発展を支えてきたのは、おもに製造業による、様々な製品の大量生産・大量販売です。優れた製品を製造単価を引き下げるために大量に作り、主に卸、小売チャネルを通じて効率よく販売していく。
メーカーにとって重要なのは、高品質な製品を開発、製造し、出荷することであり、消費者に届けるプロセスは流通業に任せる。また、購入された製品は個々の家庭、消費者が文字通り自由に利用し、消費するもの。故障時の対応はもちろん行ったものの、製品の利用・消費、そして廃棄プロセスには基本的にメーカーは関わりませんでした。
しかし、製造業以外の様々なサービス産業が勃興し発展するなかで、また製造業同士の競争も激化するなかで、製品に関連したサービス(製品の設置や、保険、利用法法を教えるコンテンツを提供するサービスなど)を併せて提供する企業が増えてきました。すなわち、モノとしての製品単体ではなく、様々なサービスなども含む「トータルソリューション」を提供するアプローチです。(ちなみに、トータルソリューションのことをマーケティングでは「ホールプロダクト(全体としてのプロダクト)と呼びます)
さらに、製品を売り切るのではなく、利用価値を継続的に提供する。つまり、月額、あるいは年額料金で貸し出す形態も近年増加してきています。いわゆる「サブスクリプション型」です。
このような、対価を得る対象が、製品からサービスに移行する変化はあらゆる業界起きています。「サービス経済」の進展ですね。
さて、サービスの特徴としては以下の4つがあります。
・無形性:サービスは物理的な存在ではありません。
・同時性:サービスは生産するそばから消費されます。例えば、理容店・美容室での散髪やスタイリングというサービスは顧客に対してリアルタイムで提供されるものです。
・変動性: 人的な要素が多い場合、サービス提供のクオリティにはばらつきが発生します。人によって良いサービスが提供されたり、逆にひどいサービスが提供されてしまう場合があります。
・消滅性:無形性、同時性の特徴と関係しますが、サービスは提供されると同時に消えていくものです。
これらの特徴のうち、プロセスに関係があるのは、同時性、変動性です。サービスとは、リアルタイムで提供され、提供されるごとにサービスの価値、クオリティに高低が生じる。したがって、サービス提供側としては、プロセスを適切に管理することが極めて重要になります。
デジタルエコノミー – デジタル化
デジタル化の端緒は、1995年のインターネット商用解禁でしょう。以降、インターネットを活用した様々なサービスが次々と誕生しました。また、消費者も、PCだけでなく、携帯電話を通じて手軽にインターネットが活用できるようになり、現在は生活のあらゆる局面においてデジタル化された機器、サービスの利用が不可欠ともなっています。したがって、デジタル化の進展が、前項のサービス化を大きく促進することになったとも言えます。
こうしたデジタルエコノミーにおいて、やはり価値を提供するプロセスの適切な管理が企業側の大きな課題となっています。オンラインの各種サービスは、しばしば実体を持つ製品の移動や消費がを伴うことがあるとしても、本質的に、前項で示した4つの特徴を備えた「サービス」です。したがって、特に同時性と変動性という難しい状況におけるクオリティコントロールが不可欠になってくるというわけです。
では、サービス化進展によるサービスエコノミー、またデジタル化の進展によるデジタルエコノミーという大きなマクロトレンドにおいて、企業が対応すべき要因について考えてみます。
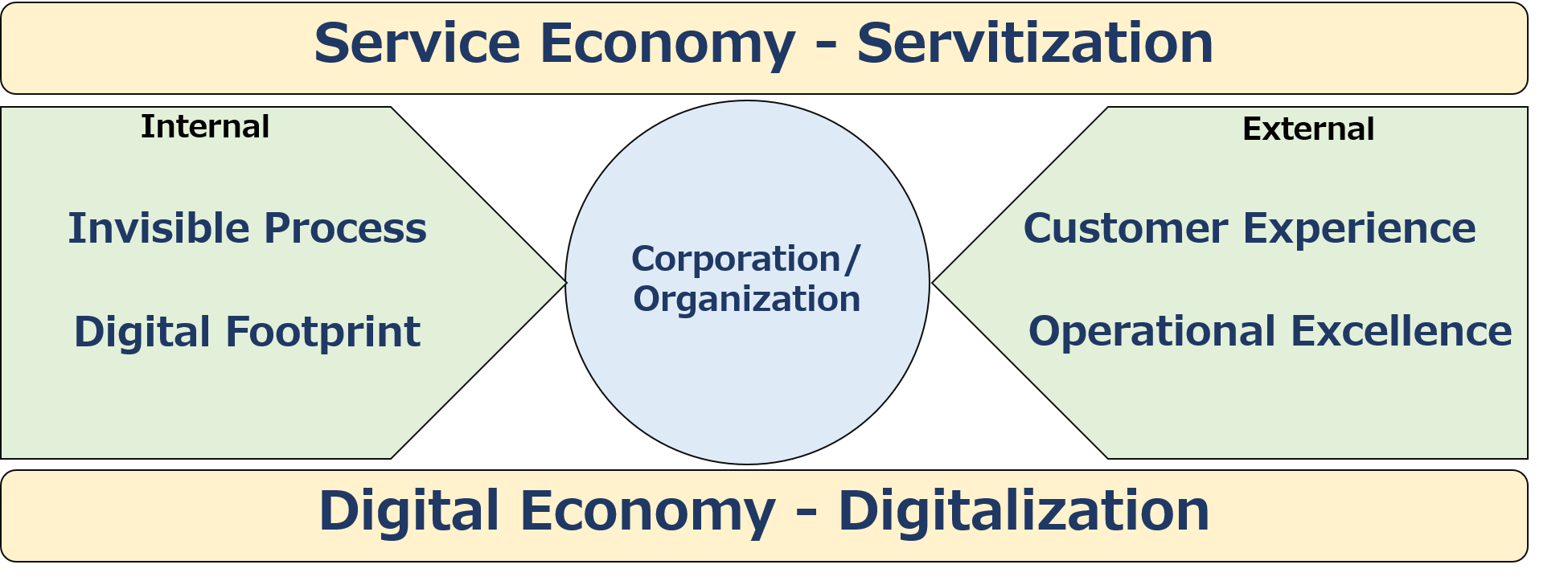
まず、外部環境についていえば、「顧客経験(Customer Experience)」、「運用の優秀性(Operational Excellence)」の2つがキーワードとして挙げられます。
顧客経験 Customer Experience
顧客経験はサービス化に深い関連があります。メーカーにとって以前は、いい製品を作って売ればそれで終わり。購入客が自社製品をどのように利用・消費するかにはほとんど注意を払っていませんでした。
ところが、製品に付随する様々なサービスを提供するようになり、またサブスクリプションでの利用が増えていく。また自社サイトを通じて直接販売するようになると、見込み客の購入行動や、製品の利用・商品から廃棄に至るプロセスを最適化することも重要になってきています。
製品自体の仕様を適切に設計するだけでなく、当該製品にまつわる顧客の購入から廃棄に至るまでの顧客経験を最高のものとする「顧客経験の設計」が必要になってきたというわけです。
運用の優秀性 オペレーショナル・エクセレンス
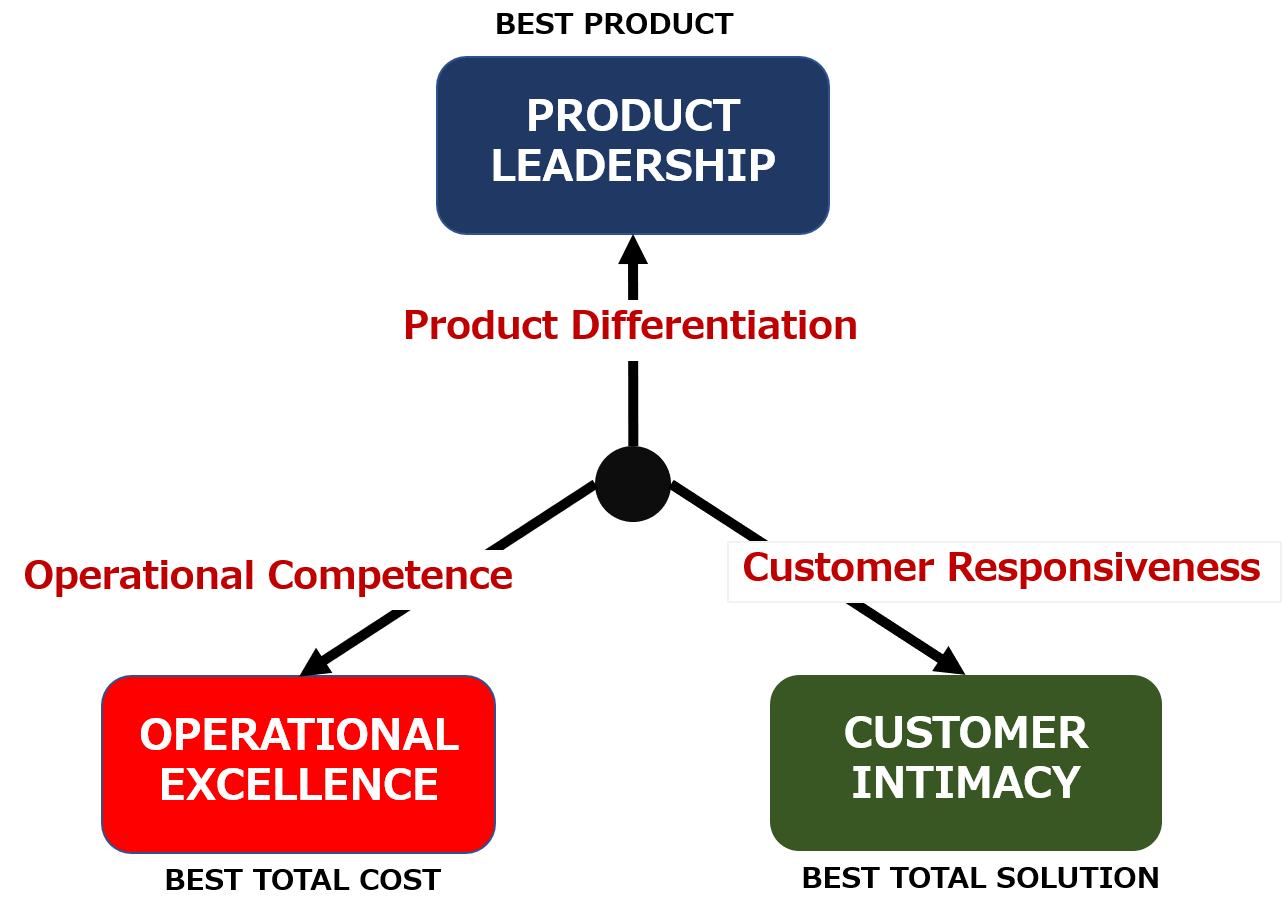
優れた顧客経験全体を考える重要性が高まる中で、競合優位性を確立するための基本戦略として重要性が高まってきたのが「運用の優秀性(Operational Excellence)」です。
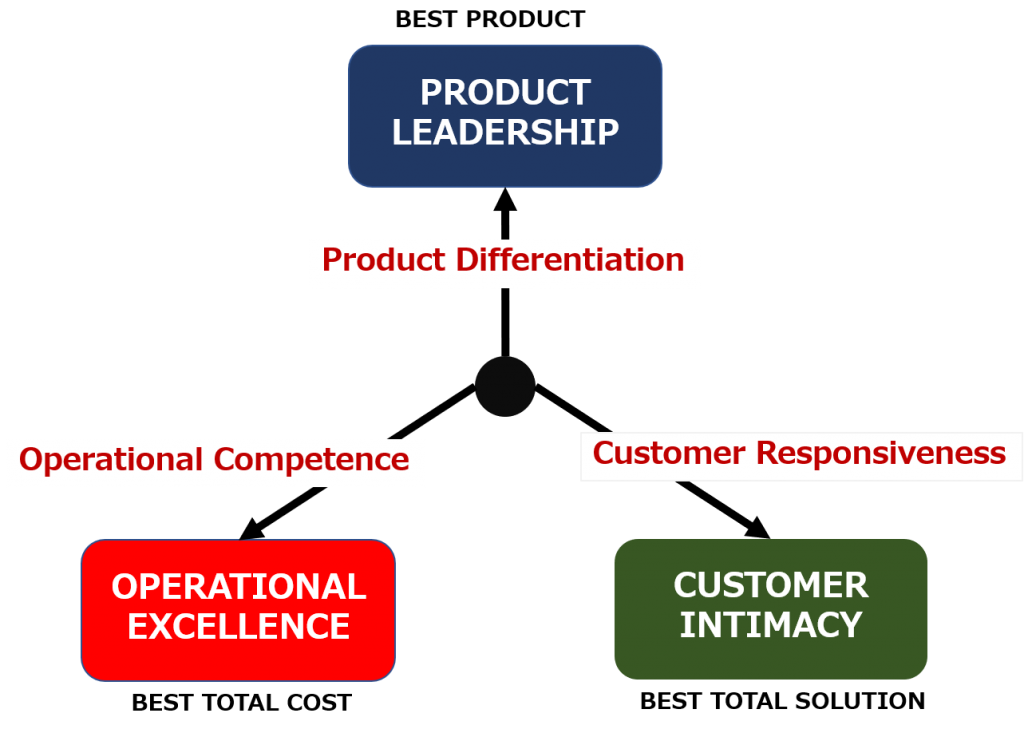
競争優位性確立のための基本戦略としては、「プロダクトリーダーシップ」、「カスタマーインティマシー」、そして「オペレーショナルエクセレンス」の3つが挙げられます。各企業は自社経営資源も踏まえ、重点を置く戦略方向を決定してきたのですが、製品そのものでの差別化がますます難しくなりつつあるため、「プロダクトリーダーシップ」の戦略の有効性は低下しています。また、顧客との親密な関係形成を狙う「カスタマーインティマシー」も、デジタル化の進展で差別化のポイントとしては十分な効力を発揮できなくなっています。
しかし、オペレーショナルエクセレンス、すなわち「運用の優秀性」は、プロセスの適切な管理に大きく関わりますが、製品、サービスの高度化・複雑化しているために一筋縄ではいかず、うまくやれる企業、やれない企業の差がつきやすい。したがって、競合優位性の確立のためには、運用の優位性に取り組むことが必要になっているのです。しかも、すぐれた運用ができるようになれば、それは顧客満足向上にもつながり、「カスタマーインティマシー」にも好ましい影響を与えるのです。
では次に内部環境について考えましょう。企業・組織の内部環境の変化は多くはデジタル化がもたらしていますが、「プロセスの非可視化」と「デジタルの足跡」の2つのキーワードを挙げましょう。
プロセス非可視化
企業においてデジタル化、すなわち、各種業務のシステム化が進展したのは1990年代のERPの登場が端緒と言えるでしょう。前述したように1995年のインターネット商用化解禁、いわゆる「インターネット革命」以降は、インターネット技術に基づく業務システム化が進展しました。さらに、Salesforce.comに代表される、莫大な初期開発コストを回避できるSaaSが次々と登場し、大企業から中小企業まで多くの企業の業務がシステム化されていっています。
問題は、業務のシステム化によって、どのように業務が行われているかが傍目からはわからなくなったことです。オフィスに全従業員が出社していて、紙と電話・FAXで業務遂行していたころは、感覚的とはいえ誰がどのように仕事を進めているかを知ることができました。
ところが、今や電話はほとんど鳴らず、各従業員はPCに向かって黙々と仕事を行っています。テレワークともなれば、もはや業務遂行状況を目で見ることはできません。
つまり、業務のデジタル化によって、多くの業務が見えないものになり、マネジメントサイドとしては、適切な進捗コントロールがとても難しくなったのです。
デジタルの足跡
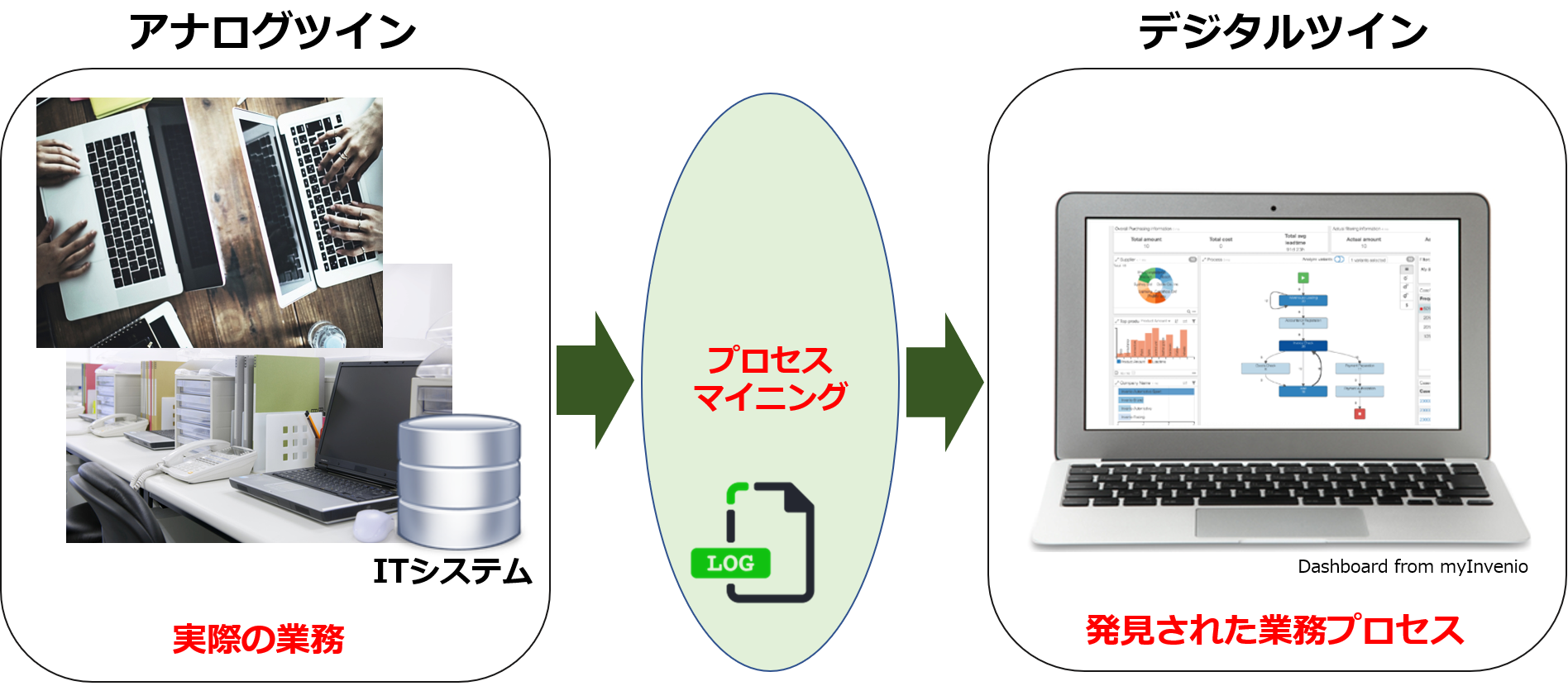
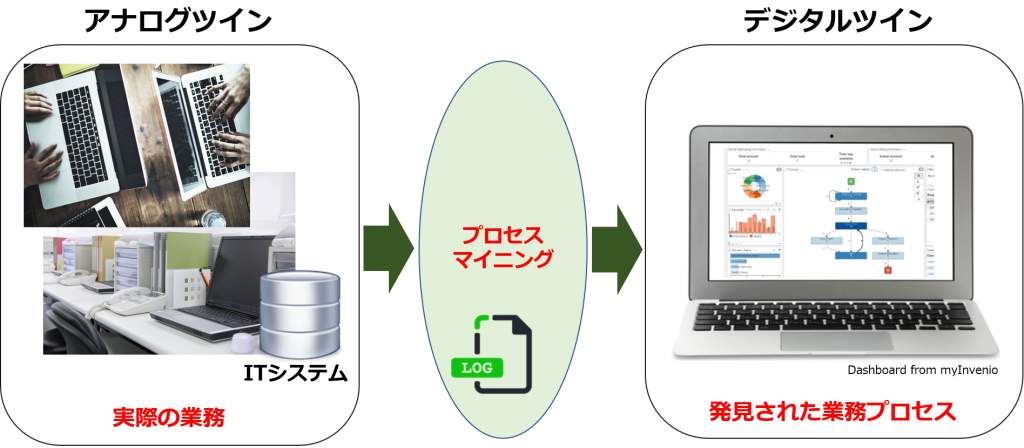
一方、業務の多くがデジタル化、システム化されたことで、システム上の操作状況をデータとしてそっくり記録可能です。「デジタルの足跡」と呼ばれますが、ERPやCRMなどのアプリケーションであれ、Excel、Powerpointなどのオフィスソフトであれ、個々のユーザーのアプリ操作履歴を捕捉・記録、分析することで、見えなくなった業務プロセスを再び「見える化」できる。
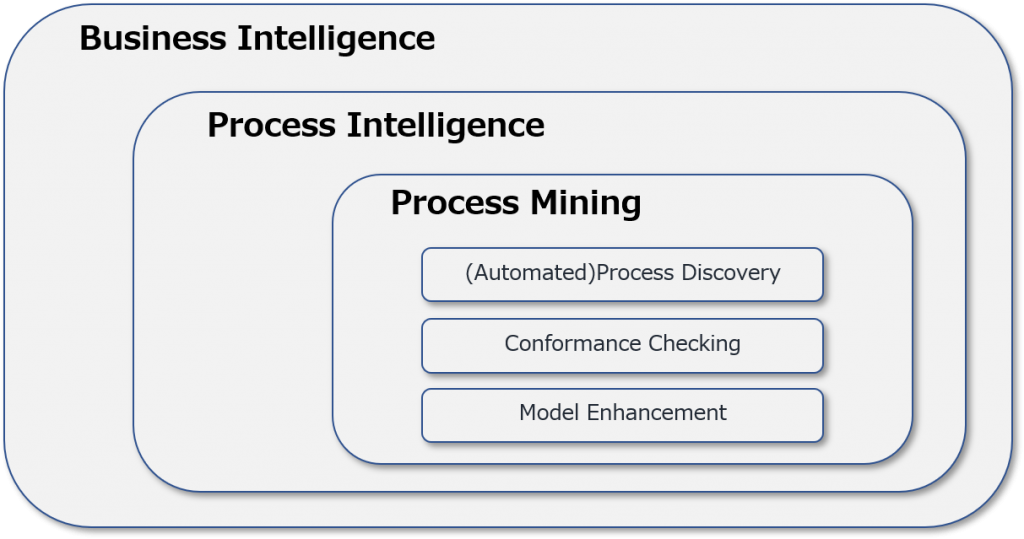
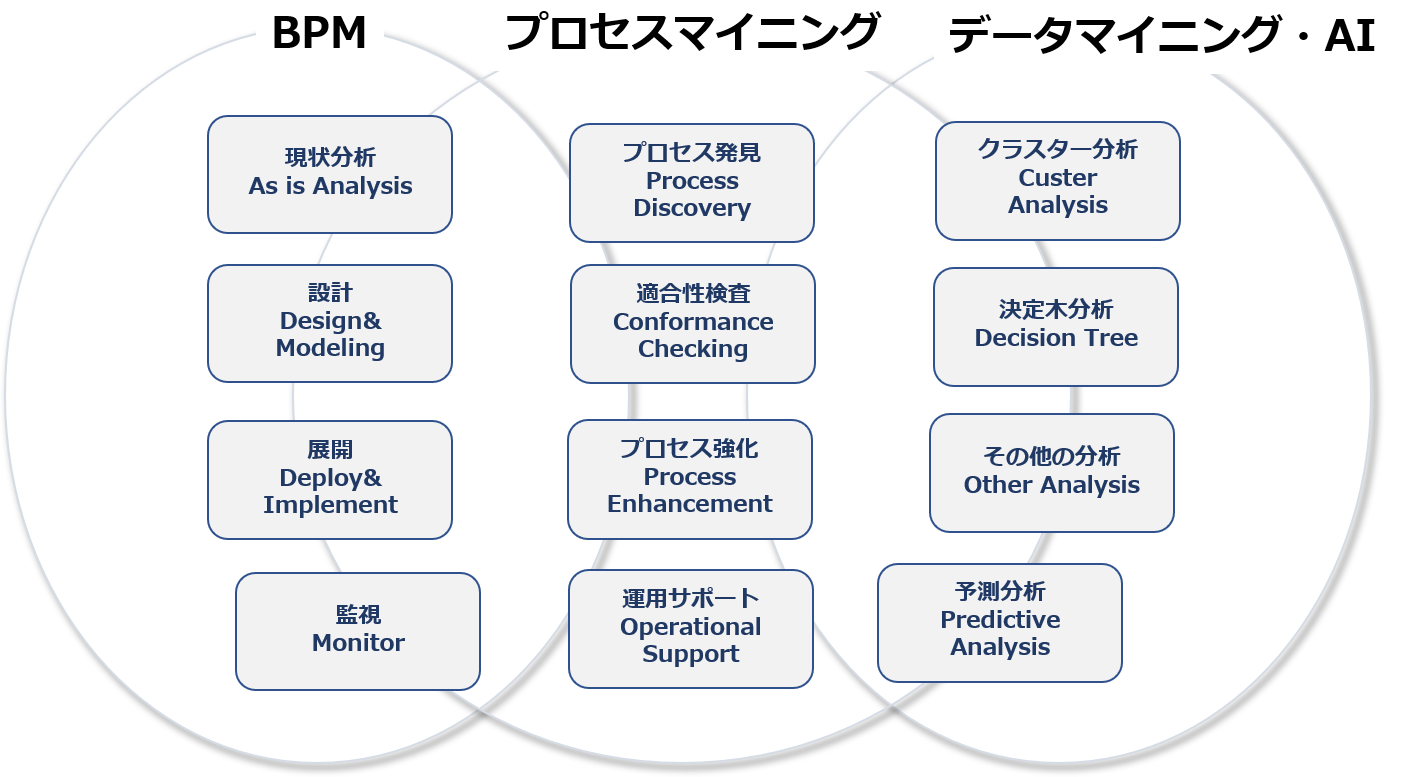
すなわち、業務システムなどから抽出したイベントログをベースに業務プロセスを自動的に再現し、継続的な業務プロセス改善に役立つ「プロセスマイニング」が、今の、またこれからの企業・組織経営に不可欠な分析手法として浮上してききた環境変化があります。
Introduction to Process Mining (3) Business environments which make process mining
In this article, I will explain the changes in the business environment in which process mining is becoming more important and indispensable.
First, there are two environmental changes that I would like to list as major trends in society as a whole. It is a “service economy” through servitization, and a “digital economy” through digitalization.
Service Economy – Servitization
Economic development to date has been supported by the mass production and sale of a variety of products, mainly by the manufacturing industry. Excellent products are made in large quantities to lower the unit cost of production and are sold efficiently, mainly through wholesale and retail channels.
The important thing for manufacturers is to develop, manufacture and ship quality products, leaving the process of delivering them to consumers to the distributors. In addition, the products purchased are literally free to be used and consumed by individual households and consumers. The manufacturer was basically not involved in the use and consumption of the product and the disposal process, although it did take care of the breakdown, of course.
However, with the rise and development of various service industries outside of the manufacturing industry, as well as increased competition among manufacturers, more and more companies are offering a combination of services related to their products (e.g., installation of products, insurance, services that provide content that teaches how to use them, etc.). In other words, our approach is to provide a “total solution” that includes a variety of services, rather than a single product as an object. (Incidentally, total solution is called “whole product” in marketing.
Furthermore, it does not sell out the product, but continues to provide value for use. In other words, the form of lending for a monthly or even annual fee has been increasing in recent years. It is a so-called “subscription type”.
This shift in the quid pro quo from product to service is happening in every industry. That’s the progress of the “service economy.
Now, there are four features of the service
Intangibility:
The service is not a physical entity.
Simultaneity:
Services are consumed as soon as they are produced. For example, the services of hair cutting and styling at barber shops and beauty salons are provided to customers in real time.
Variance in Service quality:
The quality of service delivery may vary especially when there are many human factors involved. Some people may provide good service and vice versa, others may provide terrible service.
Extinguishability:
this is related to the characteristics of intangibility and simultaneity, but services disappear as soon as they are provided.
Of these characteristics, the ones that are relevant to the process are simultaneity and variability. A service is provided in real time, and each time it is provided, there is a high or low level of value or quality of service. Therefore, as a service provider, it is crucial to manage the process properly.
The Digital Economy – Digitalization
The beginning of digitalization was the lifting of the commercial ban on the Internet in 1995. Since then, a variety of services utilizing the Internet have been born one after another. Consumers can now easily use the Internet through mobile phones as well as PCs, making the use of digital devices and services in all aspects of their lives indispensable. Therefore, it can be said that the progress of digitalization has greatly facilitated the transition to services mentioned in the previous section.
In this digital economy, proper management of the processes that deliver value has become a major challenge for companies. A variety of online services are essentially “services” with the four characteristics presented in the previous section, even if they often involve the movement and consumption of products with substance. Therefore, quality control is essential, especially in the difficult situation of simultaneity and variability.
Now, let’s look at the factors that companies need to respond to in the larger macro trend of the service economy due to the increasing use of services and the digital economy due to the increasing use of digital technology.
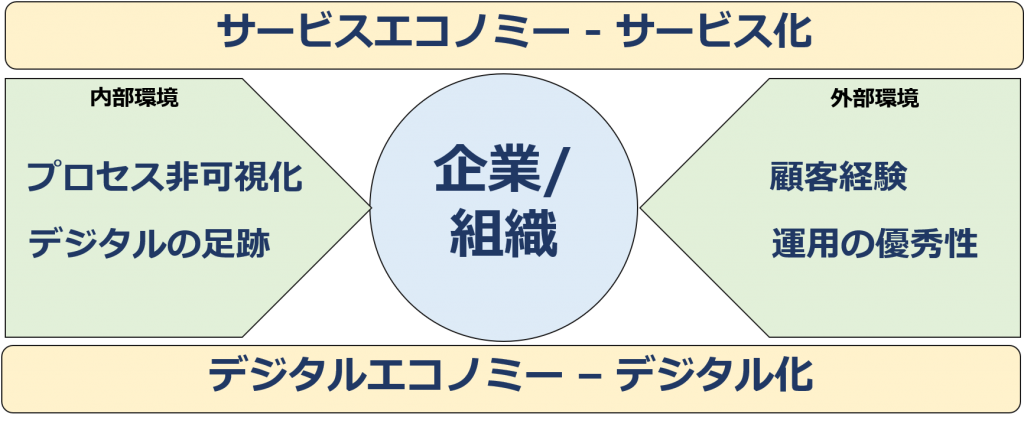
In terms of the external environment, customer experience and operational excellence are two keywords.
Customer Experience
Customer experience is deeply related to servitization. For manufacturers, it used to be that if you made a good product and sold it, that was the end of it. Little attention was paid to how purchasers would use and consume their products.
However, they began to offer a variety of services to accompany their products, and the number of subscriptions increased. As you sell directly through your own website, it is also important to optimize the buying behavior of your prospects and the process of using and disposing of your products.
It has become necessary not only to design the specifications of the product itself properly, but also to “design the customer experience” to ensure that the customer experience associated with the product, from purchase to disposal, is the best it can be.
Operational Excellence
As the overall customer experience becomes increasingly important to consider, Operational Excellence has become increasingly important as a fundamental strategy for establishing a competitive advantage.
There are three basic strategies for establishing a competitive advantage: product leadership, customer intimacy, and operational excellence. Each company has decided on a strategic direction to focus on based on its own management resources, but the effectiveness of the “product leadership” strategy has declined as it has become increasingly difficult to differentiate the product itself. In addition, customer intimacy, which aims to form an intimate relationship with customers, is no longer sufficiently effective as a point of differentiation due to the progress of digitalization.
However, operational excellence, or “operational excellence,” has a great deal to do with the proper management of processes, but due to the increasing sophistication and complexity of products and services, it is difficult to follow a straight line, and it is easy to see the difference between companies that can do it well and those that cannot. Therefore, in order to establish a competitive advantage, it is necessary to address the operational advantage. What’s more, being able to perform well can lead to increased customer satisfaction and have a positive impact on “customer intimacy”.
Now let’s consider the internal environment. While much of the change in the internal environment of companies and organizations is due to digitalization, let’s list two key words: “process de-visualization” and “digital footprint.
Intangible process
It can be said that the development of digitalization, or the systematization of various types of business operations in companies, began with the emergence of ERP in the 1990s. As mentioned above, after the lifting of the ban on the commercialization of the Internet in 1995, the so-called “Internet Revolution”, business systemization based on Internet technology has progressed. In addition, SaaS, which can avoid huge initial development costs, such as Salesforce.com, has appeared one after another, and the operations of many companies, from large corporations to small and medium-sized enterprises, are being systematized.
The problem is that the systematization of the business has made it impossible to see how the business is done from the outside. When all the employees were in the office and working by paper, phone and fax, it was possible to know who was doing what and how they were doing it, albeit in a sensory way.
Now, however, the phones rarely ring, and employees are working in silence at their computers. When it comes to telecommuting, you can no longer visually see how your work is being done.
In other words, the digitalization of operations has made many of them invisible, making it very difficult for management to properly control progress.
Digital footprint
On the other hand, since most of the business operations have been digitized and systematized, it is possible to record the status of operations on the system exactly as data. It’s called a “digital footprint,” but by capturing, recording, and analyzing each user’s application operation history, whether it’s an application such as ERP or CRM, or office software such as Excel or Powerpoint, it’s possible to “visualize” business processes that have become invisible again.
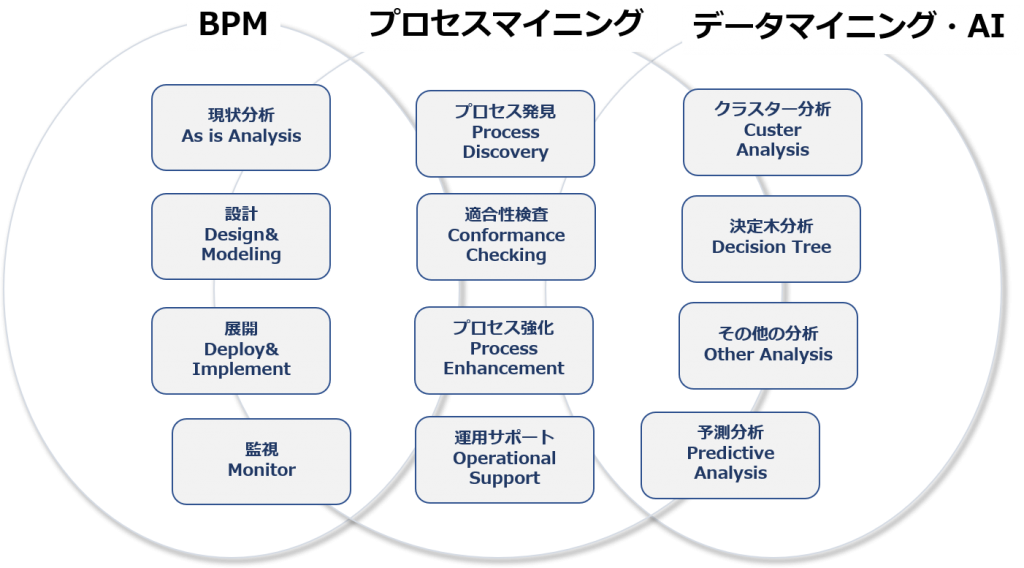
In other words, process mining, which automatically reproduces business processes based on event logs extracted from business systems, and is useful for continuous business process improvement, has emerged as an indispensable analysis method for corporate and organizational management today and in the future.